Mis Proyectos
Mayo-2021
v1.0.1 D2MCS: Data Driving Multiple Classifier System
- Adaptadas las páginas de documentación al uso de HTML5 soportado por R 4.2.0.
- Actualizada la versión de documentación roxygen2 de 7.1.1 a 7.2.1.
Agosto-2022
v3.0.3 bdpar: Big Data Preprocessing Architecture
- Adaptadas las páginas de documentación al uso de HTML5 soportado por R 4.2.0.
- Actualizada la versión de documentación roxygen2 de 7.2.0 a 7.2.1.
Mayo-2022
v3.0.2 bdpar: Big Data Preprocessing Architecture
- Eliminada la dependencia con el paquete rtweet en la clase FindEmojiPipe.
Junio-2021
v3.0.1 bdpar: Big Data Preprocessing Architecture
- Añadido a J. R. Méndez-Reboredo como autor.
Junio-2021
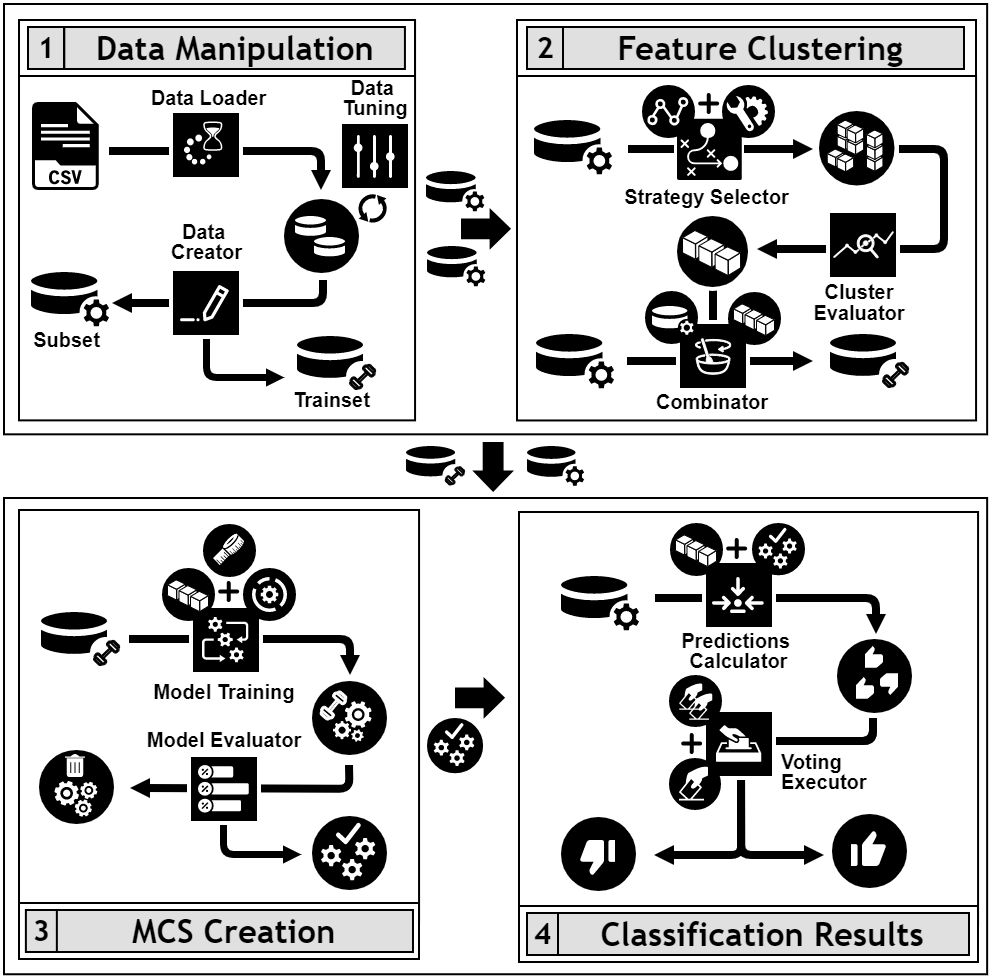
Desarrollo de técnicas de clustering no supervisado para mejorar el rendimiento de Sistemas Multi-Clasificador
El Trabajo de Fin de Máster (TFM) busca mejorar el framework D2MCS, desarrollado por el Dr. Ruano-Ordás, dirigido a la creación de un Sistema Multi-Clasificador orientado principalmente al cribado de medicamentos (in silico screening) en el ámbito farmacológico. En el transcurso de este desarrollo publicó dos artículos exponiendo los resultados obtenidos: "Improving the drug discovery process by using multiple classifier systems" y "A multiple classifier system identifies novel cannabinoid CB2 receptor ligands". El objetivo principal del TFM se basa en tres ejes básicos:
- Mejorar la capacidad de manipulación de datos.
- Ampliar las posibilidades de agrupamiento de características.
- Optimizar la precisión de la herramienta.
Mayo-2021
v1.0.0 D2MCS: Data Driving Multiple Classifier System
Framework novedoso que permite desarrollar y desplegar automáticamente un Sistema Multi-Clasificador preciso, basado en la distribución de características lograda a partir de un conjunto de datos de entrada. Para ello, D2MCS se centra en cuatro aspectos principales:
- La capacidad de determinar un método eficaz para evaluar la independencia de las características.
- La identificación del número óptimo de clusters de características.
- El entrenamiento y ajuste de los modelos de Machine Learning.
- La ejecución de sistemas de votación para combinar las salidas de cada clasificador que componen el Sistema Multi-Clasificador.
Noviembre-2020
v3.0.0 bdpar: Big Data Preprocessing Architecture
Actualización del paquete dónde se añaden funcionalidades y se solucionan errores:
Nuevas características
- Añadido un mecanismo que evita la re-ejecución de flujos de preprocesamiento para garantizar que sólo se ejecuten con nuevos datos de entrada y nuevos flujos de pipes.
- Añadida la compatibilidad para la ejecución tanto en serie como en paralelo del flujo del preprocesamiento.
- El sistema de log ha sido completamente reestructurado para soportar tanto el registro en archivo como en consola.
- Soportada la visualización del estado de las instancias entre pipes y la presentación de un resumen final de la ejecución.
- Proporciona un ejemplo para mostrar la compatibilidad con diferentes tipos de datos, por ejemplo, pre-procesamiento de imágenes.
- Actualizada la versión de la documentación soportada por el paquete roxygen2 de 6.1.1 a 7.1.1.
- Eliminadas las dependencias con varios paquetes: readr, pipeR, textutils, magrittr y purrr.
Bugs arreglados
- Corregida la ruta de los archivos de ejemplo.
- Corregido el escape de caracteres especiales al lanzar el script de Python.
- Corregido el error relacionado con no usar la función cat para guardar la información de los tweets.
Agosto-2020
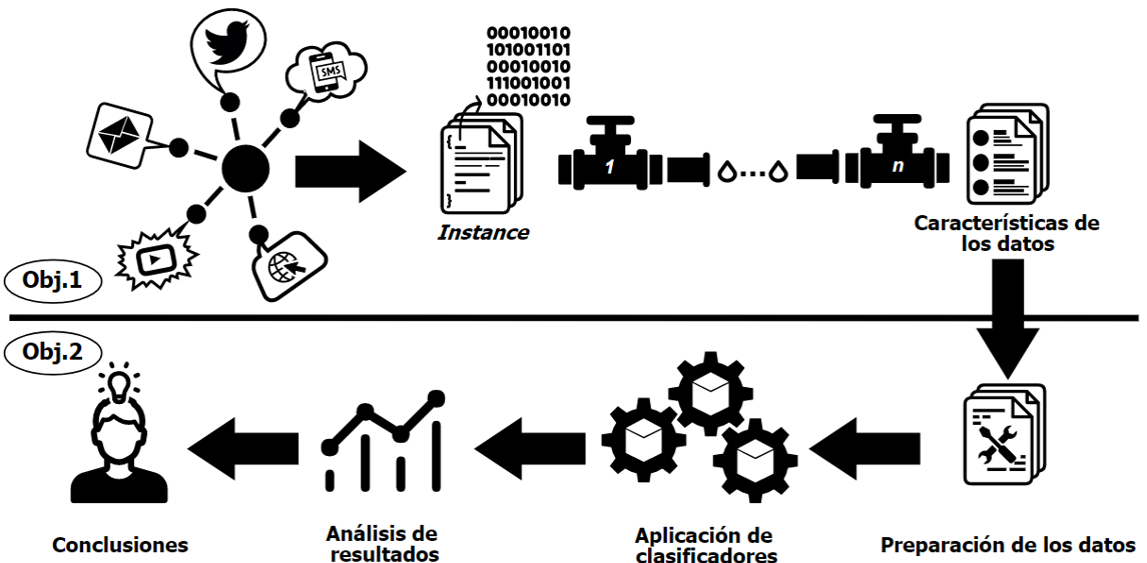
INOU-20: Extracción y pre-procesamiento de opiniones sobre el sector enoturístico en la provincia de Ourense
Proyecto realizado con el objetivo de extraer y procesar opiniones sobre las diferentes bodegas de la provincia de Ourense. Con este propósito, se utilizan enlaces de Google Maps a las diferentes bodegas para obtener de forma automática todos los datos asociados a ellas junto con los comentarios de los usuarios. Posteriormente, se realiza un pre-procesamiento de la información extraída para establecer un formato unificado y así facilitar su análisis posterior.
Noticias:
Febrero-2020
v2.0.0 bdpar: Big Data Preprocessing Architecture
Actualización del paquete dónde se añaden y se mejoran sus funcionalidades:
- El operador orientado a objetos ha sido completamente rediseñado para reducir su expresión y aumentar su funcionalidad.
- Habilitada la posibilidad de utilizar un conjunto de carpetas o archivos como entrada para el preprocesamiento.
- Remodelado el manejo de la configuración del flujo de preprocesamiento.
- Mejorado el registro de extractores de datos.
- Añadida la funcionalidad para crear dinámicamente nuevos flujos de pipes.
- Renombradas algunas funciones y clases para aumentar la legibilidad.
Julio-2019
v1.0.0 bdpar: Big Data Preprocessing Architecture
Herramienta para crear fácilmente flujos de datos personalizados para preprocesar grandes volúmenes de datos de diferentes fuentes. Con ese fin, bdpar permite:
- Utilizar y crear fácilmente nuevas funcionalidades.
- Desarrollar nuevos extractores de fuentes de datos según las necesidades del usuario. Además, el paquete proporciona por defecto un flujo de datos predefinido para extraer y preprocesar la información más relevante (tokens, fechas, ... ) de algunas fuentes textuales (SMS, Email, tweets, comentarios de YouTube).
Mayo-2019
Clasificación de contenidos de texto en diversos formatos en R usando pipes
Trabajo de Fin de Grado que consta de dos objetivos:
- La creación de una herramienta de preprocesamiento personalizada aplicando el concepto de pipe (tubería).
- Partiendo de un conjunto de datos preprocesados, se aplican los modelos de clasificación más usados; Naive Bayes, Regresión Logística, Support Vector Machine y Random Forest, para la clasificación de mensajes de textos en Legítimo/Ilegítimo.
Propiedades intelectuales
Marzo-2020
BDPAR: Big Data Pipelining Architecture for R
Autores: Miguel Ferreiro Díaz, David Ruano Ordás, Tomás Cotos Yañez y Jose Ramón Méndez Reboredo.
Julio-2021
D2MCS: Data Driving Multiple Classifier System
Autores: Miguel Ferreiro Díaz, David Ruano Ordás y Jose Ramón Méndez Reboredo.


























































